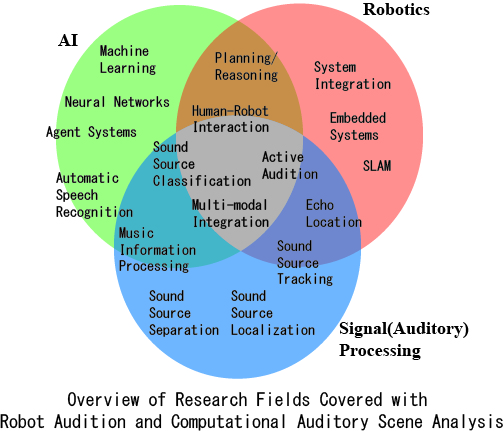
“Robot Audition” is a relatively new field of research proposed in 2000, straddling “artificial intelligence, signal processing, and robotics.” Our big theme in Robot Audition Research is how to make robots understand the surrounding sound scenes that humans normally experience. In such an environment, noise and reverberations change dynamically. For this reason, it is essential to improve noise robustness in real time in real environments where noise and reverberation are sometimes greater than the target signal. In response to these problems, we have employed elemental technology based on active audition that positively utilize robot’s own movements as the key such as location estimation of sound sources (sound source localization), extraction of target sound sources (sound source separation), and recognition of extracted sound sources (speech recognition.)
The technology that we have cultivated up to now is open to the public as Robot Audition Open Source Software HARK (Honda Research Institute Japan Audition for Robots with Kyoto University). By using HARK, for example, it is possible to build a capability like Prince Shotoku who can understand ten persons’ petitions simultaneously. Considering that the sound that humans usually hear is a mixed sound in which various sounds are intermingled, such a technique would be essential in dealing with real environments.
In recent years, we are also focusing on research such as distance estimation by audible sound, technology to restore damaged acoustic signals by deep learning, identification of acoustic signals by deep learning. If we can build such technology, we can expect to evolve robot audition research as an environment understanding technology that can understand surrounding environment
Sound Source Separation using a microphone array installed around the top of the Taxai’s head
Automatic Speech Recognition for a Mixture of 11 People’s Simultaneous Utterances by HRI-JP’s HEARBO
We are also studying new practical methods for separating sound sources from various aspects.
spot beamforming
Sound source separation based on microphone array processing uses sound direction information as a clue for separation. This means that multiple sound sources in the same direction are difficult to be separated. We are constructing a method to solve this by combining multiple microphone arrays. This technique also has an advantage of not requiring accurate synchronization of multiple microphone arrays.
surface sound source separation
Most acoustic signal processing assumes a point sound source in the model, and this is also true of microphone array processing. For example, in an outdoor concert, when we want to separate only the music from the surrounding noise, or vice versa, a surface sound source is considered in the model instead of a point sound source. To solve this problem, we propose a method for separating surface sound sources by combining multiple point sound source beam formers with a low computation.
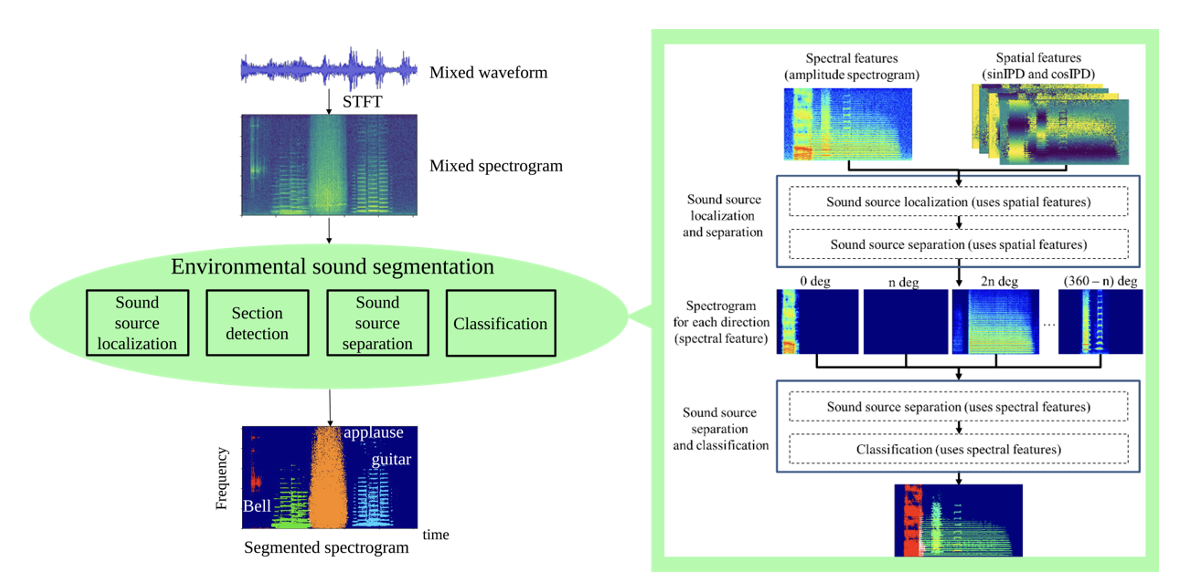
Unified framework of sound source localization, separation, and classification
In robot audition and auditory scene analysis, processes such as localization, separation, and classification are commonly integrated in a cascade manner, but such integration has a problem that errors in each process accumulate and eventually the performance of the total system deteriorates. In order to solve this problem, we propose a method that integrates these functions in an end-to-end way with deep learning.
user friendly informed source separation
In the separation of music acoustic signals, information other than acoustic signals such as musical scores can be used, which has been reported in the literature. However, such information is often expensive to create because it must be prepared manually. We propose a method to improve the separation performance simply by inputting the pronunciation timing for a part of notes.